Поисковые системы
Поисковые системы (ПС) уже давно являются обязательной частью интернета и нашей повседневной жизни. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.

Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
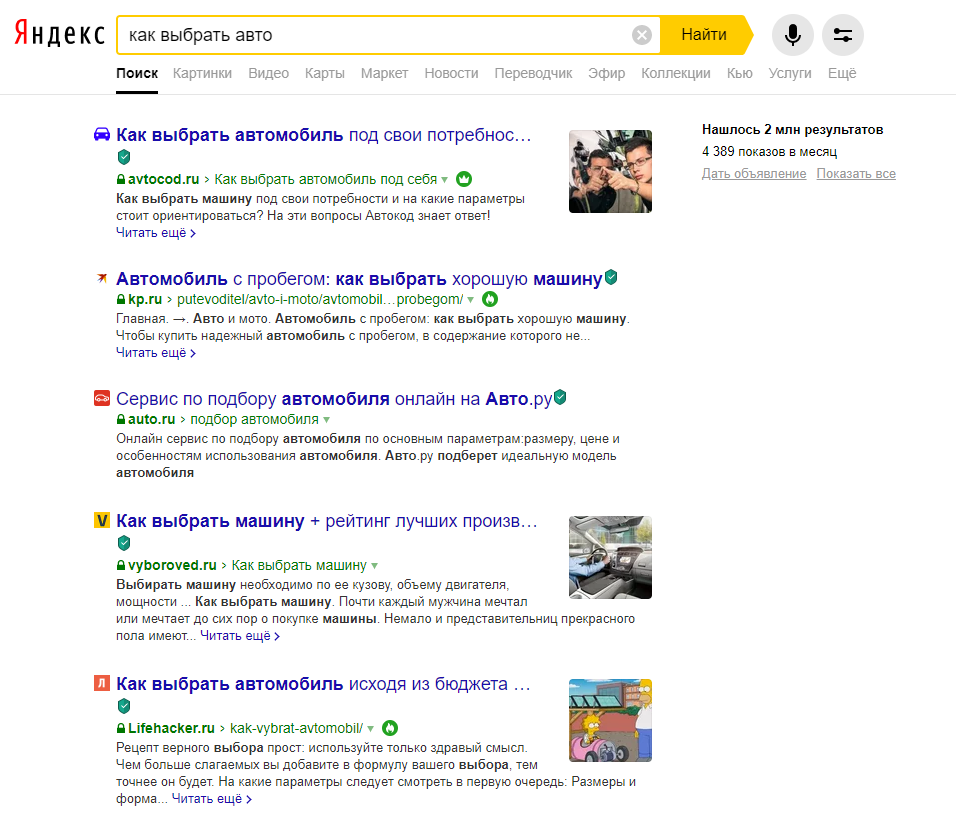
Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Туле»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. Приучить же пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?
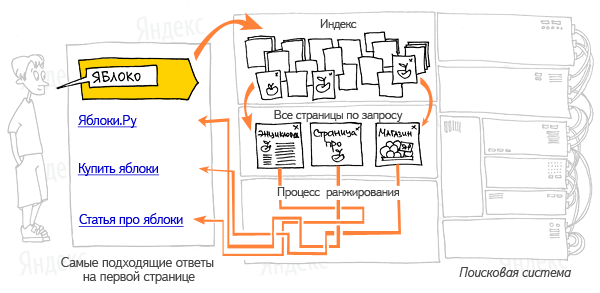
Основные характеристики поисковых систем
Полнота.
Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.
Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.
К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.
Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самым известным и большим каталогом в мире был DMOZ (прекратил работу 14 марта 2017 года) имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.
Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.

В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.

В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.

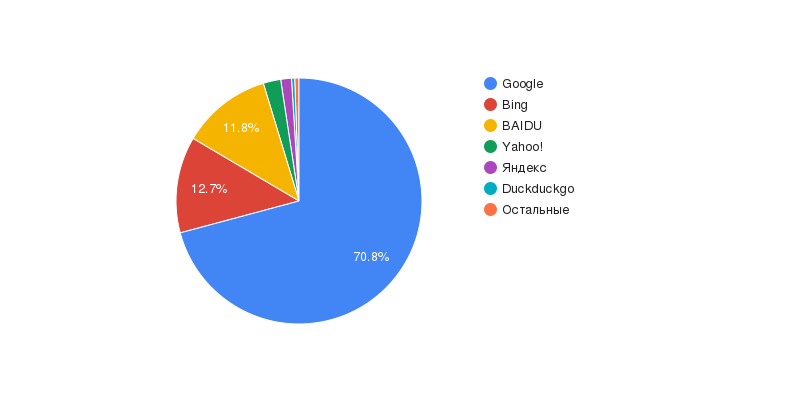
Доля поисковых систем
- Google — 70,83 %;
- Bing — 12,61 %;
- Baidu — 11,83 %;
- Yahoo! — 2,30 %;
- Яндекс — 1,41 %;
- DuckDuckGo — 0,42 %;

Принципы работы поисковой системы
Модуль индексирования.
Данный компонент состоит из трех программ-роботов:
Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.
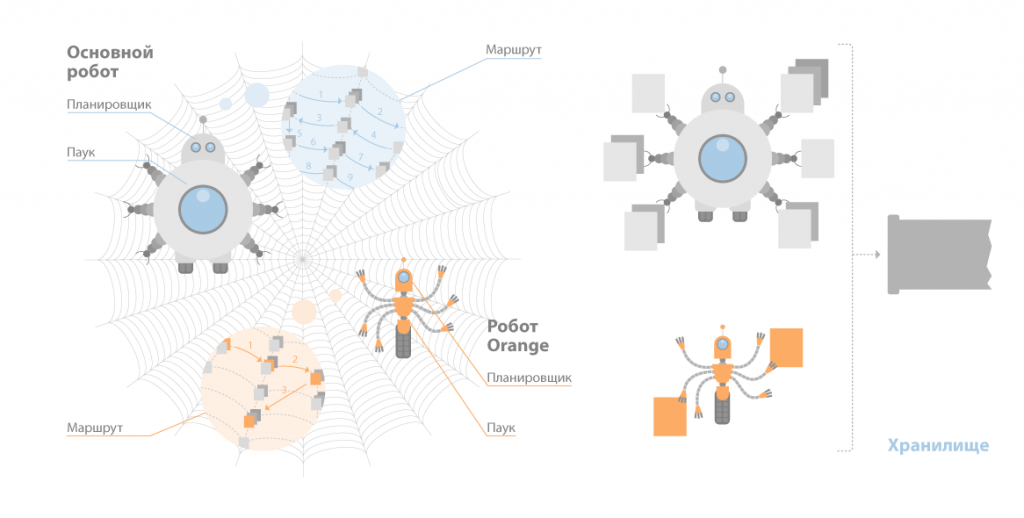
«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
Извлекаются все ссылки из тэгов. Вместе с ними обрабатывают редиректы. Любая скачанная страница сохраняется в таком формате:
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.
Crawler («путешествующий» паук). Данная программа автоматически заходит на все ссылки, которые найдены на странице, а также выделяет их. Его задача – определиться, куда в дальнейшем должен заходить паук, основываясь на этих ссылках или исходя из заданного списка адресов.
Crawler, исследуя найденные ссылки, ищет новые документы, еще не ставшие известными поисковой системе.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.
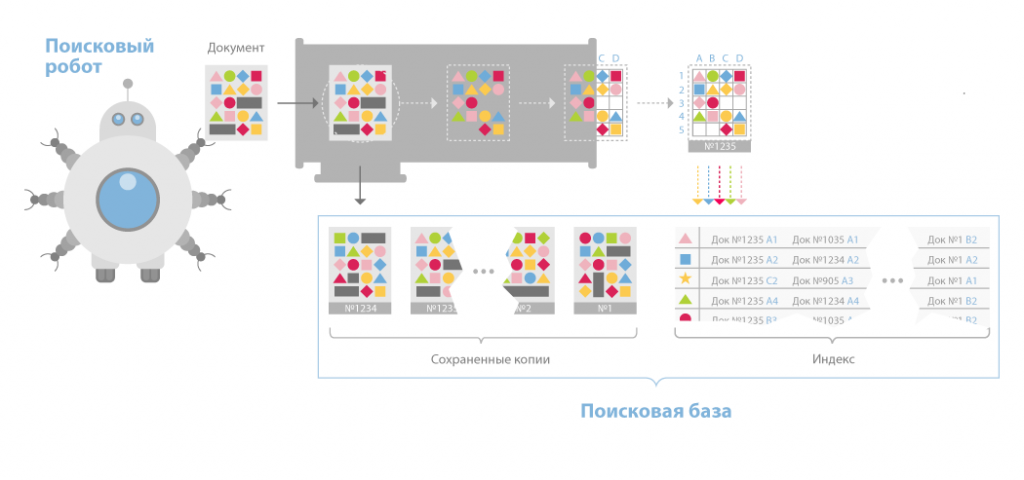
Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.
Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.
- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Все эти элементы тесно связаны между собой и функционируют, взаимодействуя, образовывая отчетливый, но достаточно непростой механизм функционирования ПС, требующий громадных затрат ресурсов.
Поисковые машины
Введение
Одним из основных способов найти информацию в Internet являются поисковые машины. Поисковые машины каждый день «ползают» по Сети: они посещают веб-страницы и заносят их в гигантские базы данных. Это позволяет пользователю набрать некоторые ключевые слова, нажать «submit» и увидеть, какие страницы удовлетворяют его запросу.
Понимание того как работают поисковые машины просто необходимо вебмастерам. Для них жизненно важна правильная с точки зрения поисковых машин структура документов и всего сервера или сайта. Без этого документы будут недостаточно часто появляться в ответ на запросы пользователей к поисковой машине или даже вовсе могут быть не проиндексированы.
Вебмастера желают повысить рейтинг своих страниц и это понятно: ведь на любой запрос к поисковой машине могут быть выданы сотни и тысячи отвечающих ему ссылок на документы. В большинстве случаев только 10 первых ссылок обладают достаточной релевантностью к запросу.
Естественно, хочется, чтобы документ оказался в первой десятке, поскольку большинство пользователей редко просматривает следующие за первой десяткой ссылки. Иными словами, если ссылка на документ будет одиннадцатой, то это также плохо, как если бы ее не было вовсе.
Основные поисковые машины
Какие из сотен поисковых машин действительно важны для вебмастера? Ну, разумеется, широко известные и часто используемые. Но при этом следует учесть ту аудиторию, на которую рассчитан Ваш сервер. Например, если Ваш сервер содержит узкоспециальную информацию о новейших методах доения коров, то вряд ли Вам стоит уповать на поисковые системы общего назначения. В этом случае я посоветовал бы обменяться ссылками с Вашими коллегами, которые занимаются сходными вопросами 🙂 Итак, для начала определимся с терминологией.
Существует два вида информационных баз данных о веб-страницах: поисковые машины и каталоги.
Поисковые машины: (spiders, crawlers) постоянно исследуют Сеть с целью пополнения своих баз данных документов. Обычно это не требует никаких усилий со стороны человека. Примером может быть поисковая система Altavista.
Для поисковых систем довольно важна конструкция каждого документа. Большое значение имеют title, meta-таги и содержимое страницы.
Каталоги: в отличие от поисковых машин в каталог информация заносится по инициативе человека. Добавляемая страница должна быть жестко привязана к принятым в каталоге категориям. Примером каталога может служить Yahoo. Конструкция страниц значения не имеет. Далее речь пойдет в основном о поисковых машинах.
Система открыта в декабре 1995. Принадлежит компании DEC. С 1996 года сотрудничает с Yahoo.
Запущенная в конце 1995 года, система быстро развивалась. В июле 1996 куплена Magellan, в сентябре 1996 — приобретена WebCrawler. Однако, оба используют ее отдельно друг от друга. Возможно в будущем они будут работать вместе.
Существует в этой системе и каталог — Excite Reviews. Попасть в этот каталог — удача, поскольку далеко не все сайты туда заносятся. Однако информация из этого каталога не используется поисковой машиной по умолчанию, зато есть возможность проверить ее после просмотра результатов поиска.
Запущена в мае 1996. Принадлежит компании Wired. Базируется на технологии поисковой машины Berkeley Inktomi.
Запущена чуть раньше 1995 года, широко известна, прекрасно ищет и легко доступна. В настоящее время «Ultrasmart/Ultraseek» содержит порядка 50 миллионов URL.
Опция для поиска по умолчанию Ultrasmart. В этом случае поиск производится по обоим каталогам. При опции Ultraseek результаты запроса выдаются без дополнительной информации. Поистине новая поисковая технология также позволяет облегчить поиски и множество других особенностей, которые Вы можете прочитать об InfoSeek. Существует отдельный от поисковой машины каталог InfoSeek Select.
Примерно с мая 1994 года работает одна из старейших поисковых систем Lycos. Широко известная и часто используемая. В ее состав входит поисковая машина Point (работает с 1995 года) и каталог A2Z (работает с февраля 1996 года).
Система OpenText появилась чуть раньше 1995 года. С июня 1996 года стала партнерствовать с Yahoo. Постепенно теряет свои позиции и вскоре перестанет входить в число основных поисковых систем.
Открыта 20 апреля 1994 года как исследовательский проект Вашингтонского Университета. В марте 1995 года была приобретена компанией America Online Существует каталог WebCrawler Select.
Старейший каталог Yahoo был запущен в начале 1994 года. Широко известен, часто используем и наиболее уважаем. В марте 1996 запущен еще один каталог Yahoo — Yahooligans для детей. Появляются все новые и новые региональные и top-каталоги Yahoo.
Поскольку Yahoo основан на подписке пользователей, в нем может не быть некоторых сайтов. Если поиск по Yahoo не дал подходящих результатов, пользователи могут воспользоваться поисковой машиной. Это делается очень просто. Когда делается запрос к Yahoo, каталог переправляет его к любой из основных поисковых машин. Первыми ссылками в списке удовлетворяющих запросу адресов идут адреса из каталога, а затем идут адреса, полученные от поисковых машин, в частности от Altavista.
Особенности поисковых машин
Каждая поисковая машина обладает рядом особенностей. Эти особенности следует учитывать при изготовлении своих страниц.
Тип поисковой машины
«Полнотекстовые» поисковые машины индексируют каждое слово на веб-странице, исключая лишь некоторые стоп-слова. «Абстрактные» поисковые машины создают некий экстракт каждой страницы.
Для вебмастеров полнотекстовые машины полезней, поскольку любое слово, встречающееся на веб-странице, подвергается анализу при определении его релевантности к запросам пользователей. Однако для абстрактных поисковых машин может случиться, что страницы проиндексированы лучше, чем для полнотекстовых. Это может исходить от алгоритма экстрагирования, например по частоте употребления в странице одних и тех же слов.
Размер поисковой машины определяется количеством проиндексированных страниц. Например, в поисковой машине с большим размером могут быть проиндексированы почти все ваши страницы, при среднем объеме ваш сервер может быть частично проиндексирован, а при малом объеме ваши страницы могут вообще не попасть в каталоги поисковой машины.
- некоторые поисковые машины сразу индексируют страницу по запросу пользователя, а затем продолжают индексировать еще не проиндексированные страницы
- другие чаще могут «ползать» по наиболее популярным страницам сети, чем по другим
Дата индексирования документа
Некоторые поисковые машины показывают дату, когда был проиндексирован тот или иной документ. Это помогает пользователю понять, какой «свежести» ссылку выдает поисковая система. Другие оставляют пользователям только догадываться об этом.
Указанные (submitted) страницы
В идеале поисковые машины должны найти любые страницы любого сервера в результате прохода по ссылкам. Реальная картина выглядит по-другому. Станицы серверов гораздо раньше появляются в индексах поисковых систем, если их прямо указать (Add URL).
Не указанные (non-submitted) страницы
Если хотя бы одна страница сервера указана, то поисковые машины обязательно найдут следующие страницы по ссылкам из указанной. Однако на это требуется больше времени. Некоторые машины сразу индексируют весь сервер, но большинство все-таки, записав указанную страницу в индекс, оставляют индексирование сервера на будущее.
Этот параметр относится только к не указанным страницам. Он показывает сколько страниц после указанной будет индексировать поисковая система.
Большинство крупных машин не имеют ограничений по глубине индексирования. На практике же это не совсем так. Вот несколько причин, по которым могут быть проиндексированы не все страницы:
- не слишком аккуратное использование фреймовых структур (без дублирования ссылок в управляющем (frameset) файле)
- использование imagemap без дублирования их обычными ссылками
Если поисковый робот не умеет работать с фреймовыми структурами, то многие структуры с фреймами будут упущены при индексировании.
Тут примерно та же проблема, что и с фреймовыми структурами серверов.
Защищенные паролями директории и сервера
Некоторые поисковые машины могут индексировать такие сервера, если им указать Username и Password. Зачем это нужно? Чтобы пользователи видели, что есть на Вашем сервере. Это позволяет как минимум узнать, что такая информация есть, и, быть может, они тогда подпишутся на Вашу информацию.
Частота появления ссылок
Основные поисковые машины могут определить популярность документа по тому, как часто на него ссылаются из других мест Сети. Некоторые машины на основании таких данных «делают вывод» стоит или не стоит тратить время на индексирование такого документа.
Способность к обучению
Если сервер обновляется часто, то поисковая машина чаще будет его реиндексировать, если редко — реже.
Показывает, какими средствами можно управлять той или иной поисковой машиной. Все крупные поисковые машины руководствуются предписаниями файла robots.txt. Некоторые также поддерживают контроль с помощью META-тагов из самих индексируемых документов.
Некоторые сайты перенаправляют посетителей с одного сервера на другой, и этот параметр показывает какой URL будет связан с вашими документами. Это важно, поскольку, если поисковая машина не отрабатывает перенаправление, то могут возникнуть проблемы с несуществующими файлами.
Некоторые поисковые машины не включают определенные слова в свои индексы или могут не включать эти слова в запросы пользователей. Такими словами обычно считаются предлоги или просто очень часто использующиеся слова. А не включают их ради экономии места на носителях. Например, Altavista игнорирует слово web и для запросов типа web developer будут выданы ссылки только по второму слову. Существуют способы избежать подобного.
Влияние на алгоритм определения релевантности
Поисковые машины обязательно используют расположение и частоту повторения ключевых слов в документе. Однако, дополнительные механизмы увеличения степени релевантности для каждой машины различны. Этот параметр показывает, какие именно механизмы существуют для той или иной машины.
Все крупные поисковые системы «не любят», когда какой-либо сайт пытается повысить свой рейтинг путем, например, многократного указания себя через Add URL или многократного упоминания одного и того же ключевого слова и т. д. В большинстве случаев подобные действия (spamming, stacking) караются, и рейтинг сайта наоборот падает.
По идее, все поисковые машины должны учитывать метаданные при индексации страниц, однако на практике не все это делают.
Этот параметр показывает как поисковые машины генерируют заголовки ссылок для пользователя в ответ на его запрос.
Этот параметр показывает как поисковые машины генерируют описания ссылок для пользователя в ответ на его запрос.
Проверка статуса URL
Очень полезная для вебмастера черта поисковой машины — можно ли проверить насколько глубоко проиндексирован его сервер и есть ли он вообще в индексе поисковой машины.